Speech Recognition in
Telecommunication Applications
By: Fidel Rodriguez
ABSTRACT
This paper presents
electronic speech recognition technology as a tool for gaining a competitive
advantage, improving customer service, and reducing costs. Speech interface applications allow
computers to recognize naturally flowing utterances from a wide variety of
users, to execute specific subroutines, and to play prerecorded
enunciations.
The telecommunications
industry is poised to greatly benefit from this technology by automating
certain call-center transactions and reducing staffing needs. However, there are risks associated with the
strategy, as customers can feel alienated or unwanted if the wrong function is
automated or the speech interface consistently malfunctions.
This paper outlines the
steps required to design, test, and deploy effective speech recognition
applications and provides a roadmap for implementing speech interfaces that are
usable, helpful, forgiving, engaging, and improve caller satisfaction. The reader will obtain the breath of
knowledge necessary to make strategic decisions regarding implementation of
speech recognition systems in a corporate environment.
CIS 540 – Survey of Voice
and Data Communications
Summer term, 2003
Bellevue University
Professor Joe Boeggeman
OUTLINE
Article I. Introduction to Speech
Recognition
Section 1.1 The case
for speech recognition
Section 1.2
Fundamental concepts
Article II. Building a Speech
Recognition Application
Section 2.1 Model
for speech production
Article
III. Deploying a Speech Recognition Application
Section 3.1 Pilot deployment phase
Section 3.2 Partial
and full deployment phases
Article IV. Conclusion
Appendix A
Article I. Introduction to Speech Recognition
Section 1.1 The Case for Speech Recognition
“There is one thing
stronger than all the armies in the world, and that is an idea whose time has
come.” Victor Hugo
Electronic speech
recognition is an idea whose time has come.
The processing power and capabilities of computers have increased beyond
expectations but the interface between humans and machines is not yet smooth,
fast, or most importantly, natural.
Electronic speech
recognition is a speech user interface (SUI) that attempts to bridge the
human-machine communication gap and follows earlier predecessors such as the
character-based user interface (CHUI), graphical user interface (GUI), and Web
user interface (WUI). Speech interface
applications allow computers to recognize naturally flowing utterances from a
wide variety of users and separate that sound from noise in the
environment. These voice messages are
translated into text form and accepted as input for controlling systems that in
turn execute specific subroutines and play prerecorded enunciations back to the
user.
This dialog leads to the
successful completion of business transactions while eliminating or minimizing
the intervention of company employees.
There is a wide range of feasible applications in the telecommunications
arena such as automating operator assisted services, conducting inbound and
outbound telemarketing campaigns, distributing calls by voice, augmenting
services for rotary phone users, providing automated customer service
information, and ordering products from catalogs. These applications make businesses more productive and efficient.
It allows the company to present a single, consistent personality to the
customer tailored to the company’s brand identity and marketing strategy.
Market leaders are beginning
to realize the benefits and savings associated with speech recognition. United Airlines created one of the first
speech recognition applications to provide flight information. The system has been running since 1999 and
receives an average of two million calls per month. Between 1999 and 2002 the system saved United Airlines in excess
of $25 million over the touchtone system that previously was in place. The system paid for itself within the first
few months of deployment (Bongiorno, 2002).
Sears, Roebuck and Co.
employed about 3,000 operators to transfer customer calls to sales associates
in specific departments. Customers
could wait as many as 20 rings before the operator answered, and one in four calls
were misdirected. The company launched
a speech recognition system to handle most of the calls going to specific
salespeople. The system handles 56% of 120,000 daily calls with a better than
90% accuracy rate (Roberts, 1999).
AirTran Airways customers
waited an average of 7 minutes on hold to obtain flight availability
information or check on flight delays.
Once connected, it would take a call center representative an additional
two and a half minutes to handle the call.
A speech recognition system reduced the wait time on hold to 2 seconds
and the call handling time to just over one minute (Lamont, 2001).
![]() Return to Outline
Return to Outline
Section 1.2
Fundamental Concepts
Social-psychological
research has shown that people treat media the same way as they treat other
people. The moment a speech recognition
system answers and asks a caller a question, the speech system becomes a social
actor (Reeves and Nass, 1996). From a
caller’s point of view, they are not just talking to a machine but to a
representative of the company and in essence, developing a perception of the
company’s ability to meet the needs of its customers.
Rabiner and Juang (1993)
identified the following fundamental concepts to follow when developing speech
recognition systems in order to meet the needs of the users.
- The system must provide a real and measurable
benefit to the user in the form of increased productivity, ease of use,
better human-machine interface, or a more natural mode of
communication. There must be a
true and lasting benefit to the user.
- The system must be user friendly. It must make the user feel comfortable
with the voice dialogue, provide friendly and helpful voice prompts, and
an effective means of communication (fall back to a live agent) when the
system fails to properly understand the spoken commands.
- The system must be accurate. It must achieve a specified level of
performance when making recognition decisions. There appears to be a nonlinear perception of
effectiveness. Meaning, systems
providing 90% or greater word recognition accuracy appear to the users as
highly accurate. Systems below 90%
word recognition accuracy appear to the users as unreliable and unusable.
- The system must respond in real time and make
the user feel that such responses come immediately (within 250
milliseconds after the end of the spoken input) so that a voice dialog can
be maintained between the user and the system.
A well-designed system takes
advantage of the above-mentioned concepts to tailor the calling experience to
the needs of the user, offers more detailed assistance to the new or infrequent
user, provides fast and streamlined services to the frequent user, and handles
errors in such a way that the communication doesn’t break down.
![]() Return to Outline
Return to Outline
Article II. Building a Speech Recognition Application
Section 2.1 Model for Speech Production
While we would like to use a
continuous recognition process, which allows the user to speak to the system in
an everyday manner without the constraint of a specific and finite vocabulary,
the fact is these systems are currently error prone and extremely expensive to
develop. A more viable solution is to
use discrete recognition. With discrete
recognition, the system recognizes a limited vocabulary of individual words and
phrases spoken by a person (Weinschenk
and Barker, 2000).
As part of their speech
recognition studies, Rabiner and Juang (1993) assembled a standard diagram
showing a typical speech production model.
Following is the reproduced diagram (color enhanced) and cursive description
of the model.
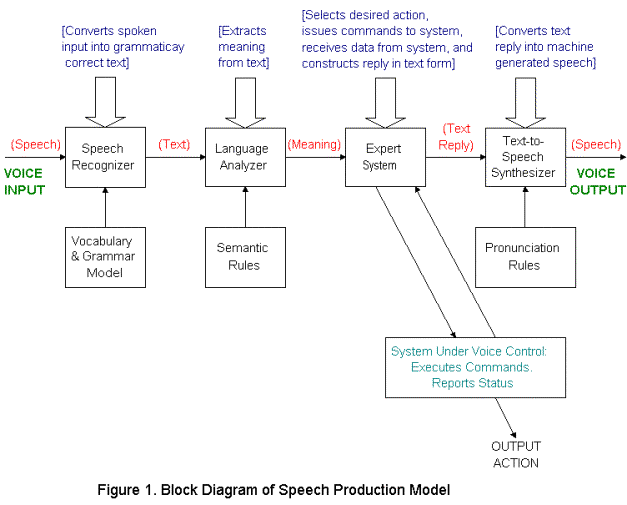
The speech production model
consists of a speech recognizer, a language analyzer, an expert system, a
system being controlled by the voice commands, and a text-to-speech
synthesizer.
Pre-defined commands are
stored in the recognizer vocabulary and grammar model and used by the speech
recognizer application to convert spoken input into grammatically correct
text. The number of stored words or
phrases can range from a few, to tens of thousands. The output of the speech recognizer is the text string most
likely to have been spoken based on the recognizer’s vocabulary and
grammar. The text string is sent to a
language analyzer to extract the meaning from the text. The decoded meaning of the input speech (in
text format) is sent to an expert system, which first selects a desired action,
issues appropriate commands to the system under voice control to carry out the
action, receives information on the command status (successful, not successful
due to X error code), and constructs a textual reply. The text-to-speech synthesizer converts the text reply into a
speech message (using appropriate word
pronunciation rules or selecting an applicable voice file) and plays it back to
the user. If information from a
database such as account number or a date is needed, the system also integrates
this information as part of the voice output.
![]() Return to Outline
Return to Outline
Section 2.2 Design
“If you can’t describe
what you are doing as a process, you don’t know what you are doing.” W. Edwards
Deming
So is the case with speech
recognition interface design. It
requires a proven design process that is efficient, results in specific
deliverables, and meets business objectives.
While there are many similarities between the design concepts for
graphical user interfaces and speech recognition interfaces, subtle differences
equire special consideration.
Weinschenk and Barker (2000) developed a voice recognition design
methodology called “InterPhase 5”.
InterPhase 5 divides the design and coding process into the following
five phases:
Investigation: The investigation phase identifies the work that has
already been done and how it can be used or modified. Project documents such as system proposal, feasibility reports,
system requirements, use cases, database entity relationship diagrams, business
process analysis, application architecture, QA test plan, marketing materials,
data flow diagrams, data dictionary, etc are evaluated to determine current
state and scope.
A checklist of the reviewed
documents and the impact on the interface design is produced. After the investigation is completed, a
project plan describing the work remaining to be done and identifying missing
components from an interface design and usability point of view is created.
Analysis: The analysis
phase defines who the users are, how they work presently, and how they are
expected to work in the future. A
description of the speech interface requirements from the user’s point of view
is created. The following documents can
be used to gather a full set of requirement specifications during the analysis
phase.
- A description of the overall functional goal of
the system
- A description of the callers and calling
behavior
- A description of the specific functions of the
system
- A description of the database functionality that
will provide the information to the application and the components to be
used
- A description of the feel of the system, including
any elements of the company brand
- A list of specific, measurable goals for the
system
Conceptual Model Design: This is a
model of how the users will see the interface, not the underlying or actual
software structure. Scenarios and
scripts are used to describe how users will interface with the system. It includes navigation flowcharts showing
all possible interaction combinations from the user’s point of view focusing on
the common dialog or conversation path first.
Exception processing can be modeled after details from the common path
are completed. Navigation flowcharts
can be used to provide a bird’s-eye view of the system and ensure the interface
will match the user’s natural call progression flow.
Detail Design: In this
phase the analysis and conceptual model information is used to create an actual
online prototype of the application.
Storyboards and sketches are used to conduct walkthroughs with users and
key stakeholders to get feedback and make changes to the interface. A usable interface is created after multiple
iterations of the design are reviewed in a collaboratively environment. The design is inspected to be sure it meets
industry standards and specific corporate standards.
It is essential to develop a
testing plan while conducting detail design.
All relevant stakeholders participate and the detailed system
functionality knowledge gained determines the specific components that need to
be tested. A testing plan should
include the following sections:
- The objective of the test
- A description of methodology
- A schedule of participants
- A description of testing scenarios
- A description of testing location, facilities,
and equipment
- Scripts for the participants to follow as part
of testing
- Questionnaires or surveys
- A post-test interview form for the testers
The deliverable from the
detail design phase is a design document containing a script for each dialog,
specific data that will be passed to the transaction systems, specific data
that will be returned, and desired voice output that will be spoken to the
user. The detailed design document is
delivered to the programming team for coding and the testing plan is used as
part of usability testing.
Evaluation and
Implementation: In this phase, implementation relates to the
work done by the development team during programming and unit testing. User testing and deployment is done
later. The development team evaluates
the design specifications with the design team to make sure requirements are
clearly stated and feasible. The
development and design teams work closely throughout the coding period to solve
any technical or design issues that might come up.
The output from this phase
is a revised design document including all changes made to the specifications
and the latest version of the application meeting unit testing requirements.
![]() Return to Outline
Return to Outline
Section 2.3 Testing
After the software coding and unit testing phases are completed,
it is necessary to conduct usability tests before a speech recognition system
can be deployed on a large scale. Dr.
Hura (2002) defines usability testing as “a
method for evaluating the quality of the caller experience for speech-enabled
applications. It reveals diagnostic information on how to improve the
application to better satisfy customers. Usability testing offers the
opportunity to identify and eliminate problems within speech applications
before unveiling them to the public, resulting in time and cost savings for
enterprises deploying such applications. As a result, customers are satisfied
using the application and call center costs are thereby reduced”.
There are differences between the commonly used methodologies for
testing graphical user interfaces and usability tests for speech recognition
interfaces. For example, when testing a
speech recognition system, test subjects cannot speak out loud to provide
feedback or get clarification from the testing director because that would
cause the speech recognizer to malfunction. Instead they would have to come up
with other forms (such as raising the hand, waving a flag, etc) to get the
testing director’s attention.
The work done by Kotelly (2003) provides excellent insights regarding speech recognition systems testing and deployment and presents key questions designers must keep in mind when testing speech recognition applications.
- Can people use it?
- Do they form a correct
mental model of the application so they can continue to use it? Can they
extend their mental model so that they are confident to interact with
other areas of the system?
- What should the test
subjects be doing at each point to get their tasks accomplished?
- What are the test
subjects doing at each point, and if they are not doing the right or
optimal things, what are they doing?
- What are the
similarities and differences between the mental model of the system that
the subject is forming and the mental model that the designer intended?
- Do they enjoy using
the system?
The accurate formation of a user’s mental model requires special
attention. A mental model represents the image people using the system form in
their head. For example, how to
navigate through the system, what voice commands to use in a particular situation,
what to do if the system doesn’t understand their commands, how to ask for
assistance, etc. A successful speech
recognition system must closely match the users mental model with the way the
way the system actually works.
![]() Return to Outline
Return to Outline
Article III. Deploying a Speech Recognition Application
Section 3.1 Pilot Deployment Phase
“There is simply no
substitute for real callers making real calls under real world conditions.” Blade
Kotelly
The above quote elegantly
makes a case for seeking customer involvement and developing a phased approach
to speech recognition systems deployment.
Here again, we are faced with a fundamental difference between the
deployment of graphical user interface applications and speech user interface
applications. In a graphical interface,
it is possible for internal users and the quality assurance department to test
every potential input and to identify and reject incorrect entries. However, the intricacies of a speech
recognition system mandates a different approach; one that must involve the end
customer. With a speech recognition
system each individual’s mental model, voice tone, pitch, accent, loudness, and
environmental noise play a role in making the voice input into the system
unique.
In the pilot deployment
phase, only a few hundred real calls are allowed into the system so designers
and programmers can tune up the recognizer, the design of the user interface,
the prompts, and solve any technical glitches.
This is the longest deployment phase because all data analysis work is
done manually and the majority of the system changes are done. The participants should be representative of
the calling population to ensure that results will be accurate and
modifications will benefit the entire customer base. A few techniques can be used to route people into the speech
recognition system. For example a
percentage of the calls can be selected, or each 100th call can be
selected. It is advisable to play a
quick message letting customers know about the new system and the current
limited use. This helps prepare them
for any potential problems encountered with the system.
Because real customers are
using the system in a live production environment, there has to be a process
for quickly routing all calls back to their original destination if the system
malfunctions or the majority of customers are encountering problems using the
system or being recognized by the system.
Analysis of the pilot
deployment output can be performed by viewing statistics such as the average
call duration and the average number of transactions processed. However, the best technique is to actually
listen to the call dialog either via live silent monitoring or by playing saved
audio files that include both the customer’s utterances and the system
replies. Experienced system
administrators are able to examine the speech dialog from the caller’s point of
view and determine if the objective of the call was met and if the system
performed as expected. Calls can be
categorized as success, failure, or unknown.
Fine-tuning of the system in a pilot mode continues until the failure
rate drops to 5% or lower at witch time the next phase of deployment can start
(Kotelly, 2003).
![]() Return to Outline
Return to Outline
Section 3.2 Partial and Full Deployment Phases
A 95% success rate indicates
the system is working well and it is time to increase the number of calls. The emphasis during partial deployment
should be on further fine-tuning the system and improving it. Analysis continues by implementing
statistical reports and sporadically monitoring live telephone calls. Increasing call volumes can be routed into
the system over a period of weeks to months based on system complexity and
business requirements.
This phase also provides an
opportunity to analyze call trends and patterns to further optimize the process
and improve efficiency. For example,
calls can go faster by streamlining or shortening prompts or by cutting out
unnecessary pauses in the prompts.
“Some subtle improvements in deployed systems have been known to
contribute to a savings of one million dollars a year – accomplished simply by
editing some of the prompts” (Kotelly, 2003).
There is not a clear-cut
transition from the partial deployment phase into the full deployment
phase. Rather, it is a seamless
process. Full deployment occurs when
the system is stable and taking 100% of the calls. Call analysis and monitoring is still done but on a very limited
basis. Improvements to a fully deployed
system should be minor and subtle to limit the impact on live operations and
customer service.
Finally, transaction
completion reports are regularly monitored to identify sudden drops in call
completion efficiency so corrective action can be taken. Processes should be put in place to
continually improve the usability of the application, to fine-tune the system
for maximum performance, and to update the application as necessary to meet
changing business requirements or customers’ needs.
![]() Return to Outline
Return to Outline
Speech recognition is a technology ready for prime time. There is ample evidence that early adopters
like United Airlines have reaped considerable financial gains and not only
improved customer service, but also retained and augmented their client
base. Common sense dictates that when
you make it easy for your customers to do business with you, your customers
will stay with you.
The speech recognition system’s ability to closely mimic natural
human communication is unique and clearly sets it apart from other
systems. However, this uniqueness
introduces a new set of system design, testing, and deployment challenges that
information technology executives and administrators must understand and
overcome.
This paper provided specific information to help bridge the
knowledge gap and ensure a successful system implementation. Fundamental concepts to follow when
developing speech recognition interfaces were outlined. A speech production model diagram showed the
different components of a speech recognition system and their functions. Design and testing methodologies applicable
to speech interfaces were presented together with a three-tiered phased
approach to system deployment.
The guidelines and techniques presented in this paper provided a
framework of reference for interested individuals to implement speech
recognition systems that positively contribute to the bottom line of their
organizations and generates superior levels of customer service and retention.
![]() Return to Outline
Return to Outline
Appendix A
Perhaps the best way to become familiar with speech recognition
technology is to actually try it. I
encourage you to dial the telephone number appearing below and try the system
yourself.
Company: United
Airlines
Function: Provide arrival and departure
flight information
Telephone: 1-800-824-6200
Mental Model:
You are a Bellevue University student residing in Omaha and need
to pick up a friend at the airport. You
know he is flying out of La Guardia airport in New York and arriving in Omaha
today around 10:00 AM but you don’t know the flight number, departure time, or
exact arrival time. You want to call
flight information to find out what time the flight is supposed to arrive and
the current flight status so you can make plans.
Even if you call late in the day and after 10:00 AM, you will get
information like the actual arrival time of the flight so you will know how
long your friend has been sitting at the airport waiting for you!
Dial 1-800-824-6200
You should be greeted by a male voice and
asked for a flight number or instructed to say I don’t know it
Say “I don’t know it”
The system will
ask if you want arrival or departure information
Say “arrival”
The system will
ask the departure city
Say “New York”
The system will let you know there are multiple airports in the New York area and give you a listing of airports to select from
Say “La Guardia”
The system will
ask the arrival city
Say “Omaha”
The system will ask what time you think
the flight is arriving in Omaha
Say “Ten O’clock”
The system will ask if it is in the
morning or the evening
Say “morning”
The system will confirm all information
is correct and process your inquiry. You will be provided with arrival
information on a flight closely matching your selections.
Additional information:
Here is a case study providing additional information and a recorded
demonstration of the United Airlines system.
http://www.speechworks.com/customers/customer_detail.cfm?id=4#
SpeechWorks is United’s speech recognition system developer.
![]() Return to Outline
Return to Outline
Appendix B
While conducting research for this paper, I came across a very
interesting write-up in the On-Line Education section of the International
Engineering Consortium. The article is titled Speech-Enabled Interactive Voice
Systems and can be found at http://www.iec.org/online/tutorials/speech_enabled/index.html?Back.x=20&Back.y=15
The article is very informative, easy to read, and relevant to the
speech recognition body of knowledge.
Particularly, the attached Continuous Improvement Cycle diagram provides
a refreshing view of the system development cycle and very closely matches the
methodologies advocated by other authors quoted in the paper.
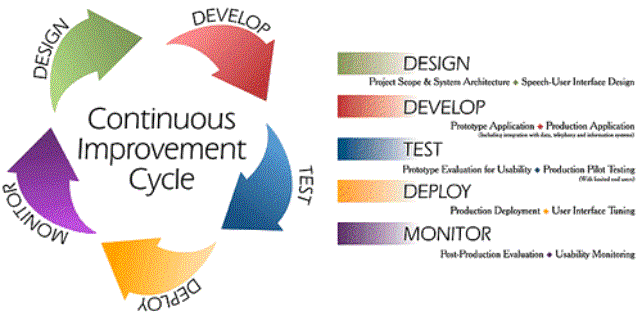
This continuous improvement cycle model is applicable to any
software development project and can be used by systems administrators and
project managers to illustrate the system development and implementation
process.
The International Engineering Consortium fully supports the use
and distribution of their materials for information purposes as per their
copyright notice shown below.
Copyright Notice
Everything on this site is copyrighted. The copyrights are owned by the International Engineering Consortium (IEC) or the original creator of the material. However, you are free to view, copy, print, and distribute IEC material from this site, as long as:
1.
The
material is used for information only.
2.
The
material is used for non-commercial purposes only.
3.
Copies
of any material include IEC copyright notice.
![]() Return to Outline
Return to Outline
Bongiorno, Bob, Managing
Director of Customer Service, Planning and Finance Applications, United
Airlines. At SpeechWorks International Global Speech Day “Web Seminar”, 2002.
Hura, Susan L. (2002) The
Value of Usability Testing for Speech-Enabled Applications. Speech Technology
Magazine. Sept 24, 2002. Also available online at http://www.speechtechmag.com/pub/industry/1215-1.html
Kotelly, Blade. (2003). The
Art and Business of Speech Recognition. Boston, MA: Addison-Wesley.
122-123, 136, 147-148
Lamont, Ian. (2001). Speech
Recognition Technology Will Hear You Now. Retrieved from CNN.com on July 3rd,
2003. http://www.cnn.com/2001/TECH/industry/06/06/auto.speech.idg/
Lindquist, Christopher.
(2000). Phones Still Don’t Listen. Retrieved from CIO.com on July 4th,
2003. http://www.cio.com/archive/061500_et_revisit.html
Rabiner, Lawrence and Juang,
Biing-Hwang. (1993). Fundamentals of Speech Recognition. New Jersey:
Prentice Hall PTR. 483, 485-486
Reeves, Byron and Nass,
Clifford. (1996). How People Treat Computers, Television, and New Media Like
Real People and Places. New York: Cambridge University Press.
Roberts, Bill. (1999). Speech
Recognition Fosters Better Customer Service Through Self-Service. Retrieved
from CIO.com on July 4th, 2003. http://www.cio.com/archive/051599_et.html
Weinschenk, Susan and
Barker, Dean T. (2000). Designing Effective Speech Interfaces. New York:
John Wiley & Sons, Inc. 99, 270
![]() Return to Outline
Return to Outline